
문제 : boj13548
우선 가장 간단한 방법으로, 각 쿼리마다 직접 해당 범위를 순회하면서 가장 많은 등장 수를 찾는 것은 당연히 간단하다. 하지만 그러면 O(MN)이 될 것이므로 시간초과가 나게 된다.
그러니 이번엔 이전 쿼리의 결과를 이용할 방법을 생각해보자. 첫 번째 쿼리가 i=3, j=10이고 두 번째 쿼리가 i=5, j=11 이라고 해보자. 그림으로 나타내면 아래와 같다.

이 경우 만약 위에서 말한 방법대로 매번 직접 순회하며 볼 경우 첫 번째 쿼리는 8번, 두 번재 쿼리는 7번을 봐야하므로 총 15번을 봐야한다. 하지만 첫 번째 쿼리에서 i가 +2가 됬으므로 주황색으로 빗금친 부분을 빼면 2번을 빼면 되고, 마찬가지 방식으로 파란 빗금부븐을 1번 더해줄 수 있다. 그럼 총 15번 필요했던게 3번으로 줄어든다!
하지만 위 방법으로 하려면 어떻게 가장 많이 나온 수를 찾을 수 있는지 쉽게 파악되지 않을 것이다. 내 경우엔 이걸 위해 배열 2개를 사용했다.
cnt[x]는 현재 보고 있는 범위내에 x가 나온 횟수이다. bucket[y]는 범위내의 임의의 x에 대해 cnt[x]가 y인 횟수이다. 이렇게 해주면 어떠한 수를 포함시키는 경우와 빼는 경우로 나눌 수 있다.
다음의 예시를 보자.
5
1 1 3 3 1
3
2 3
1 5
3 4
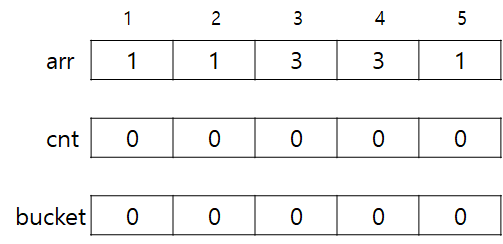
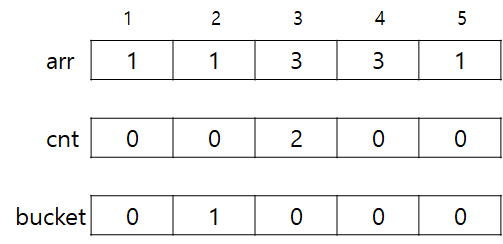
1. 시작은 다음과 같다. arr은 입력값, cnt와 bucket은 위에서 설명한 배열이다.
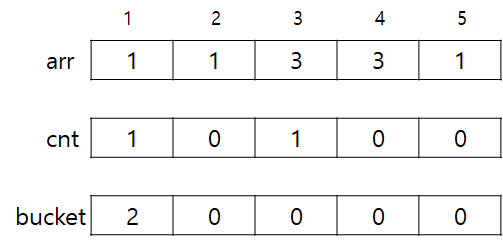
2. 우선 첫 번째 쿼리인 [2, 3]을 추가하면 다음과 같이 된다. 이 때 가장 많이 나온 횟수는 1회이다. answer이 현재 쿼리에 대한 답이라고 하자. answer = 1이다.
3. 이제 [2,3]에서 [1,5]로 쿼리를 변경해보자. i값은 2->1, j값은 3->5 이므로 추가만 해주면 된다. 이 때 추가하는 과정은 arr 내의 특정 값 x에 대해 ++bucket[++cnt[x]] 라고 할 수 있다. 그리고, 이 값이 1이 된다면 해당 횟수를 가지는 값이 새로 추가된 것이고 그렇다면 해당 횟수가 정답이 될 가능성이 생긴다. 따라서 현재 answer보다 cnt[x]가 더 크다면 answer = cnt[x]로 변경해주면 된다.
우선 j값을 3->5로 변경하면서 cnt와 bucket에 추가해준 결과는 다음과 같다.
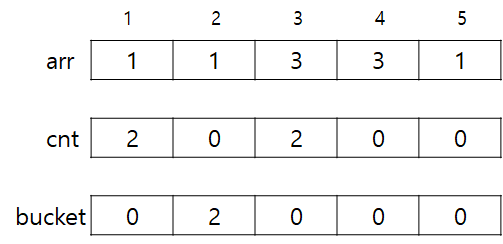
현재까지의 answer은 2이다.
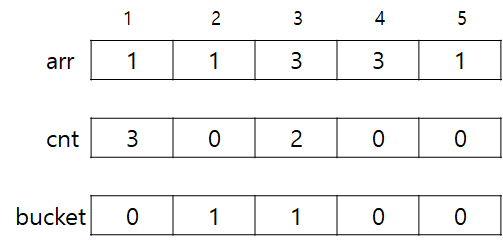
그리고 i도 2->1로 변경하면서 추가해주면 다음과 같다. ++bucket[++cnt[1]]의 결과가 1이 됬고, cnt[1]은 3이 됬으므로 answer이 3으로 증가됨을 확인할 수 있다.
4. 이번엔 [1,5]에서 마지막 쿼리인 [3,4]를 해보자. i는 1->3이므로 2개를 빼줘야하고, j도 5->4 이므로 1개를 빼줘야한다.
이 때 --bucket[cnt[x]]가 0이 됬는데, answer이 cnt[x]와 동일한 경우에만 answer이 변경되게 된다. cnt[x]가 이후 1이 빠질 것이므로 무조건 answer은 -1을 해주면 된다. 진행한 결과는 다음과 같고, answer은 2가 된다.
------
위와 같은 방식으로 한다면 이전 쿼리의 결과를 이용해서 연산 횟수를 줄이면서도 매번 cnt를 증가 혹은 감소할 때 마다 O(1)로 answer을 찾을 수 있다. 참고로 bucket 없이 cnt 배열만 존재할 경우엔, 추가할 때는 answer을 찾을 수 있지만 제외할 때는 answer을 찾기위해 O(N)이 필요하게 된다(예를들어 bucket[3]=2이고 answer=3인 경우, cnt[x]가 3이었던걸 제외시킨다면 bucket[3]=1이 되어 현재 보고 있는 cnt[x]말고 또 다른 값이 횟수가 3회로 남아있음을 알 수 있어서 answer을 감소시키지 않을 수 있다).
다만 위의 로직 만으론 시간초과를 피하기 힘들다. 다음을 생각해보자.
처음에 쿼리를 입력받을 때 쿼리의 순서를 따로 기록해둔다면, 사실 쿼리의 순서는 마음대로 바꿔도 된다. 왜 바꾸려고 하냐면, 다음의 쿼리 입력을 생각해보자.
...
3
1 100000
1 1
1 90000이걸 위의 방식대로 순서대로 처리할 경우 처음에 약10만번을 추가해주고 -> 그다음 약10만번을 제외해주고 -> 마지막으로 약9만번을 추가해줘야 한다. 총 합 29만번을 해줘야 한다. 차라리 매번 범위 전체를 보면 19만번으로 더 횟수가 적어진다.
하지만 이걸 다음의 순서로 변경하면 총합 10만번으로 횟수가 적어진다.
1 1
1 90000
1 100000
이런식으로 [i, j] 범위가 매번 바뀌고, 이전의 결과값을 이용하는 경우 효율적으로 순서를 정렬하는 알고리즘으로 Mo's algorithm이 있다. 이 글 등을 참고해보자. 대략의 방식은 n개의 원소가 있는 경우, [i, j] 범위를 i/sqrt(n) ASC, j ASC 순서로 정렬하는 것이다.
위에서 설명한건 메인이 되는 개념으로, 세세하게 처리해줘야 하는 부분은 이하의 코드를 참고해보자.
코드 : github
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.Arrays;
import java.util.StringTokenizer;
class Query implements Comparable<Query> {
int a, b, idx, compFactor;
static int sqrtN;
public static void setSqrtN(int n) { sqrtN = (int)Math.sqrt(n); }
public Query(int a, int b, int idx) {
this.a = a;
this.b = b;
this.idx = idx;
this.compFactor = this.a/sqrtN;
}
@Override
public int compareTo(Query o) {
if (this.compFactor == o.compFactor)
return this.b-o.b;
return this.compFactor-o.compFactor;
}
}
public class Main {
int[] cnt = new int[100010];
int[] bucket = new int[100010];
int answer = 0;
private void push(int num) {
bucket[cnt[num]]--;
if (++bucket[++cnt[num]]==1 && cnt[num]>answer) answer = cnt[num];
}
private void pop(int num) {
if (--bucket[cnt[num]]==0 && answer==cnt[num]) answer--;
bucket[--cnt[num]]++;
}
private void solution() throws Exception {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
Query.setSqrtN(n);
int[] arr = new int[n+1];
StringTokenizer st = new StringTokenizer(br.readLine());
for (int i = 1; i <= n; i++) arr[i] = Integer.parseInt(st.nextToken());
int m = Integer.parseInt(br.readLine());
Query[] queries = new Query[m];
for (int i = 0; i < m; i++) {
st = new StringTokenizer(br.readLine());
queries[i] = new Query(Integer.parseInt(st.nextToken()), Integer.parseInt(st.nextToken()), i);
}
Arrays.sort(queries);
for (int i = queries[0].a; i <= queries[0].b; i++) push(arr[i]);
int[] ansArr = new int[m];
ansArr[queries[0].idx] = answer;
int a = queries[0].a;
int b = queries[0].b;
for (int i = 1; i < m; i++) {
Query q = queries[i];
for (int x = q.a; x < a; x++) push(arr[x]);
for (int x = b+1; x <= q.b; x++) push(arr[x]);
for (int x = a; x < q.a; x++) pop(arr[x]);
for (int x = q.b+1; x <= b; x++) pop(arr[x]);
a = q.a;
b = q.b;
ansArr[q.idx] = answer;
}
StringBuilder sb = new StringBuilder();
for (int i = 0; i < m; i++) sb.append(ansArr[i]).append('\n');
System.out.print(sb);
}
public static void main(String[] args) throws Exception {
new Main().solution();
}
}'PS > BOJ' 카테고리의 다른 글
| [자바] 백준 2154 - 수 이어 쓰기 3 (boj java) (0) | 2022.06.11 |
|---|---|
| [자바] 백준 8462 - 배열의 힘 (boj java) (0) | 2022.06.10 |
| [자바] 백준 24513 - 좀비 바이러스 (boj java) (0) | 2022.06.08 |
| [자바] 백준 24508 - 나도리팡 (boj java) (0) | 2022.06.08 |
| [자바] 백준 14725 - 개미굴 (boj java) (0) | 2022.06.08 |




댓글